算数运算
算数运算要与赋值语句结合才会生成代码
1 | 5 + 6; // 无效语句 |
加法
常量 + 常量
1 | int i = 5 + 6; |
编译器不会生成5+6的指令,而是在编译期间就算出5+6的值11,并将其赋值给i
变量 + 常量
1 | i = i + 1; |
编译器使用add指令完成加法
变量 + 变量
1 | i = i + j; |
也是使用add指令完成加法
减法
减法与加法类似,只不过指令是sub。但是有时候计算机会使用加法补码来完成减法。
x - 2
= x + (-2)
= x + 2(补)
乘法
乘法指令有有符号乘法imul以及无符号乘法mul两种。规则也与上面类似,下面说一下特例
乘数是2的幂
使用左移代替乘法指令
1
2
3
4i = i * 16;
mov eax, dword ptr [ebp-4]
shl eax, 4 // 左移4位
Debug版以及Release版都会转换
组合运算
当组合运算中的乘数为2、4、8时,组合运算会用lea指令替代
1
2
3
4
5i = i * 4 + 5;
mov ecx, dword ptr [ebp-4]
lea edx, [ecx*4+5]
mov dword ptr [ebp-4], edx
lea指令是取址指令,周期要比mul短
而乘数非2、4、8时,会按照正常流程执行
乘数非2的幂
1 | i = i * 15; |
Debug版注重调试,直接使用乘法指令替代
Release版本会将乘数分解因子,尽量使用低周期指令代替(强度削弱)。例如上例是这样分解的
i * 15
= (i * 3) * 5
= (i + i * 2) * 5
= eax * 5
= eax + eax * 4
整数除法
在C语言中,整数除法有三种情况
- 两个无符号整数整除,结果是无符号的
- 两个有符号整数整除,结果是有符号的
- 有符号整数与无符号整数混除,结果是无符号的,有符号的符号位会被当成数据位看待
除法指令有有符号除法idiv以及无符号除法div两种,下面看看特殊情况
除数是2的幂
1 | i = i / 2; |
除以2的幂可以通过右移来实现。
在除法中,除数需要放到指定的寄存器eax中。cdq命令将eax的最高位复制到edx中,实际上就是位数扩展。下面是一个很奇怪的减法: eax = eax - edx。实际上这里巧妙地实现了一个分支结构。
我们知道:
3 / 2 = 1
-3 / 2 = -1
除法是向0取整的
但是当我们使用右移代替除法时
3 >> 1 = 1
-3 >> 1 = -2
11111101 >> 1 = 11111110
由于右移丢失最后位,因此右移实际上是向下取整的!当除数为正数时,向下取整没问题;但除数为负数时,我们需要对其+1再右移,就能避免位数丢失造成的取整异常(这里有数学证明)。
所以现在的逻辑是
1 | if(eax < 0) eax += 1; |
再回顾上面的cdq指令,当eax为负数时,edx是11111111(-1);当eax为正数时,edx是00000000(0)。使用eax-edx,恰好就能实现上面的分支结构!
最后右移幂位数完成除法。
除数非2的幂
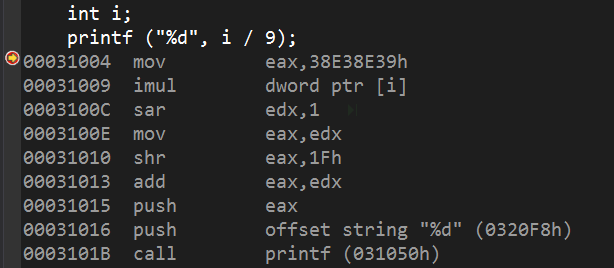
这里编译器进行了一次强度削弱,使用乘法指令以及移位指令代替除法指令。具体方法如下
设x是变量,o是常量,则
$$\frac{x}{o} = x \ast \frac{1}{o} = x \ast \frac{2^n}{2^n \ast o} = x \ast \frac{2^n}{o} \ast \frac{1}{2^n}$$
由于$o$在编译期间已知,$n$是编译器选择的,因此$\frac{2^n}{o}$可以在编译期间算出,这个数也被称为Megic Number(魔数、幻数),例子中是0x38E38E39。
我们可以通过移位的个数以及魔数还原出被除数o。
至于上面的shr以及add指令,实际上也是做了一个分支结构,当eax是负数的时候,右移31位的出来的值是1,否则是0,它等价于
1 | if (eax < 0) eax += 1 |
也是避免位移造成的取整异常
变体
- Magic Number超出4字节整数的表示范围
- 除数为负数
- Magic Number > 0x7FFFFFFF,当除数是正数
- Magic Number < 0x80000000,当除数是负数
逻辑运算与关系运算
三元运算符
表达式1 ? 表达式2 : 表达式3
- 1为常量,则在编译器得出结果,不会存在指令
- 2或3是变量,则不会优化
- 2和3是常量,优化
- 1是简单比较,2和3的差值等于1
- 1是简单比较,2和3的差值大于1
- 1是复杂比较,2和3的差值大于1
1是简单比较,2和3的差值等于1
1 | return argc == 5 ? 5 : 6; |
使用cmp以及setne实现比较以及+1
1是简单比较,2和3的差值大于1
1 | return argc == 5 ? 4 : 10; |
等价于reg == A ? C : B+C
使用sub以及neg实现比较,使用add实现赋值(表达式2) 然后利用sub结果配合and实现赋值(表达式3),当表达式3小于表达式2时,add的值是负数
1是复杂比较,2和3的差值大于1
区间比较属于复杂比较
1 | return argc <= 8 ? 4 : 10 |
综合两种优化方案
使用cmp实现比较,add实现赋值,and实现另一种情况的赋值
流程语句
Debug下的if 与 if -else 语句
1 | if (argc > 0) { |
1 | jxx ELSE_BEGIN // 相反的比较 |
Release下的if 与 if -else 语句
几乎与三元运算符一致
Debug下的if -else if -else语句
1 | jxx ELSE_IF_BEGIN_1: |
不难发现,对于每一层if与else,实际上都是一样的格式
1 | jxx NEXT_ELSE_IF_OR_ELSE // 相反的比较,跳到下一层 |
Release下的if -else if -else语句
1 | void func(int i){ |
对于这种只有if语句的函数来说,执行了其中一个分支就不需要跑到其他地方去了。编译器会使用Rutn指令进行优化
1 | void func(int i){ |
这样子就能节省一个jmp语句了
switch 语句
switch语句与多重if -else if -else语句的区别是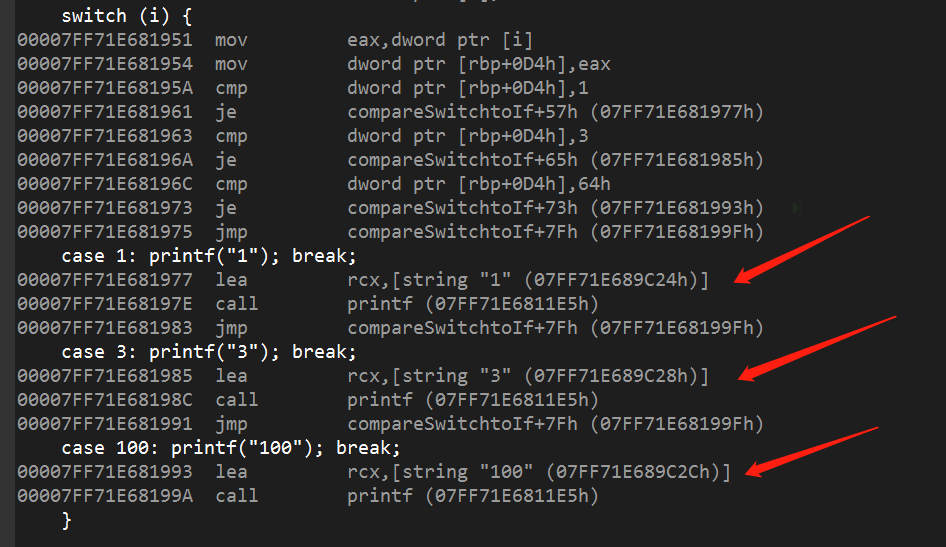
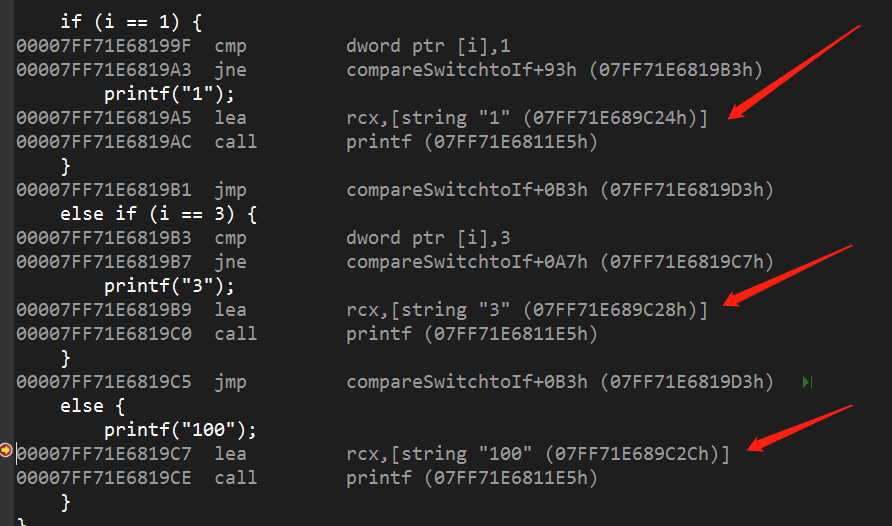
if语句在条件判断指令后面就跟着要执行的指令
switch语句将所有要执行的指令都存放到后面,以便没有break的时候顺序执行
在switch分支数小于4的情况下,VC++6.0会模拟成if语句提高效率
switch语句的线性优化
当判定值存在明显线性关系的时候,switch会使用数组存放判定值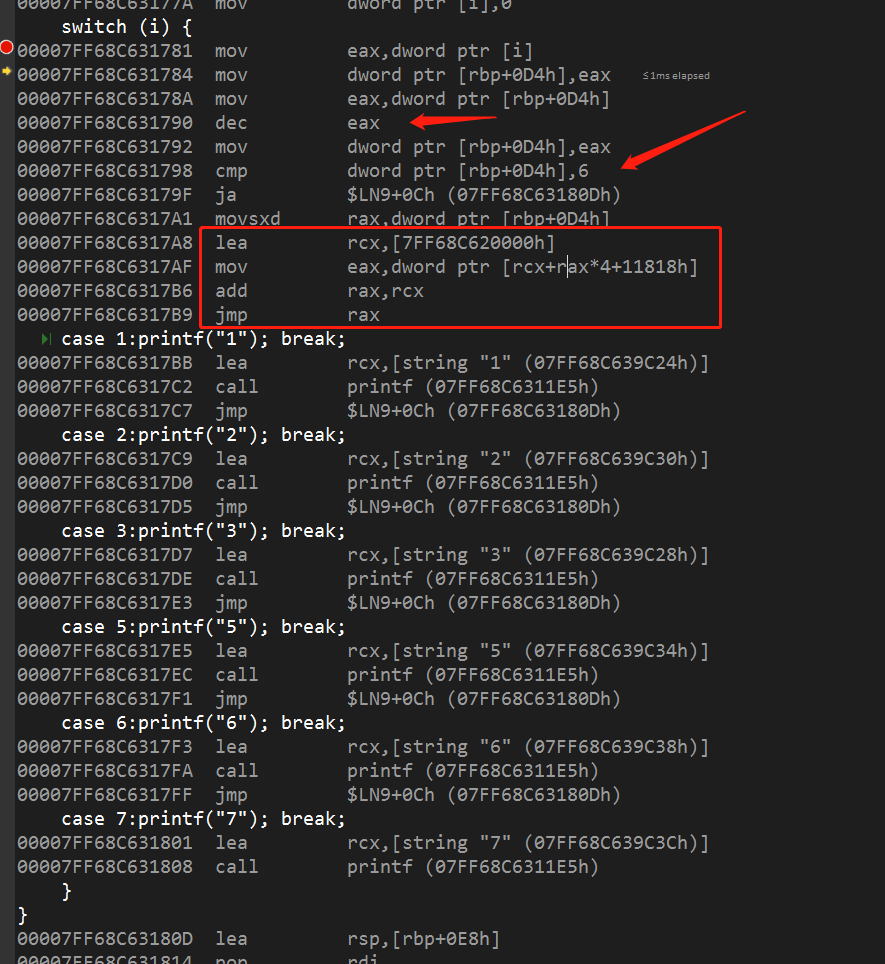
由于判定值从1开始,所以插入dec eax使i减一,然后就可以直接使用i的值作为索引查找数据了cmp dword ptr [i], 6是范围确定,在这里只有6个判定值,因此数组大小也只有6,超过了就直接跳过
最后红框处我们可以看到,rcx寄存器保存了数组的基地址,11818是数组的偏移地址,由于一个地址占int4个字节,所以eax需要乘以4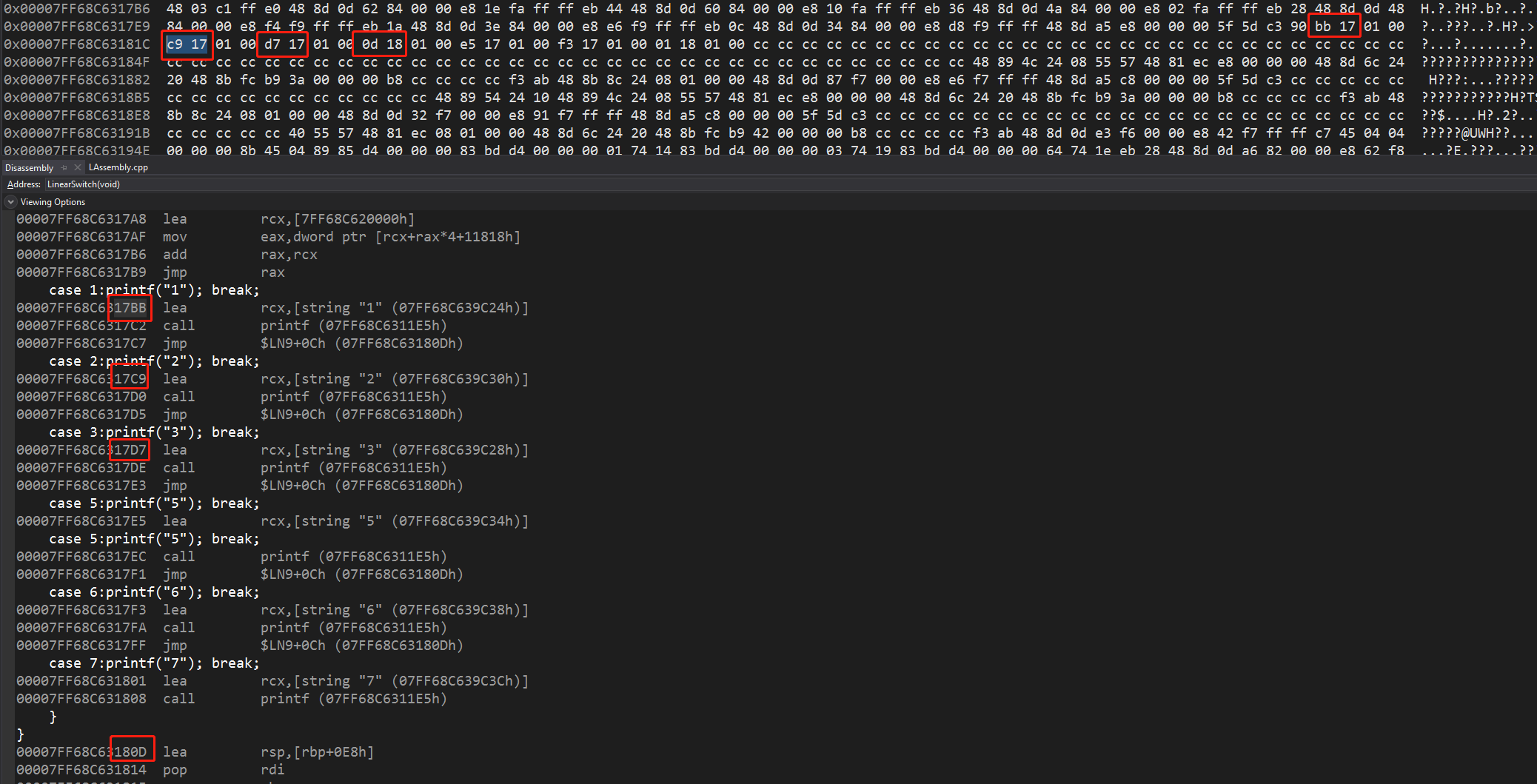
switch语句的索引优化
当最大判定值与最小判定值的差小于等于255的时候,switch语句使用索引表+地址表的形式优化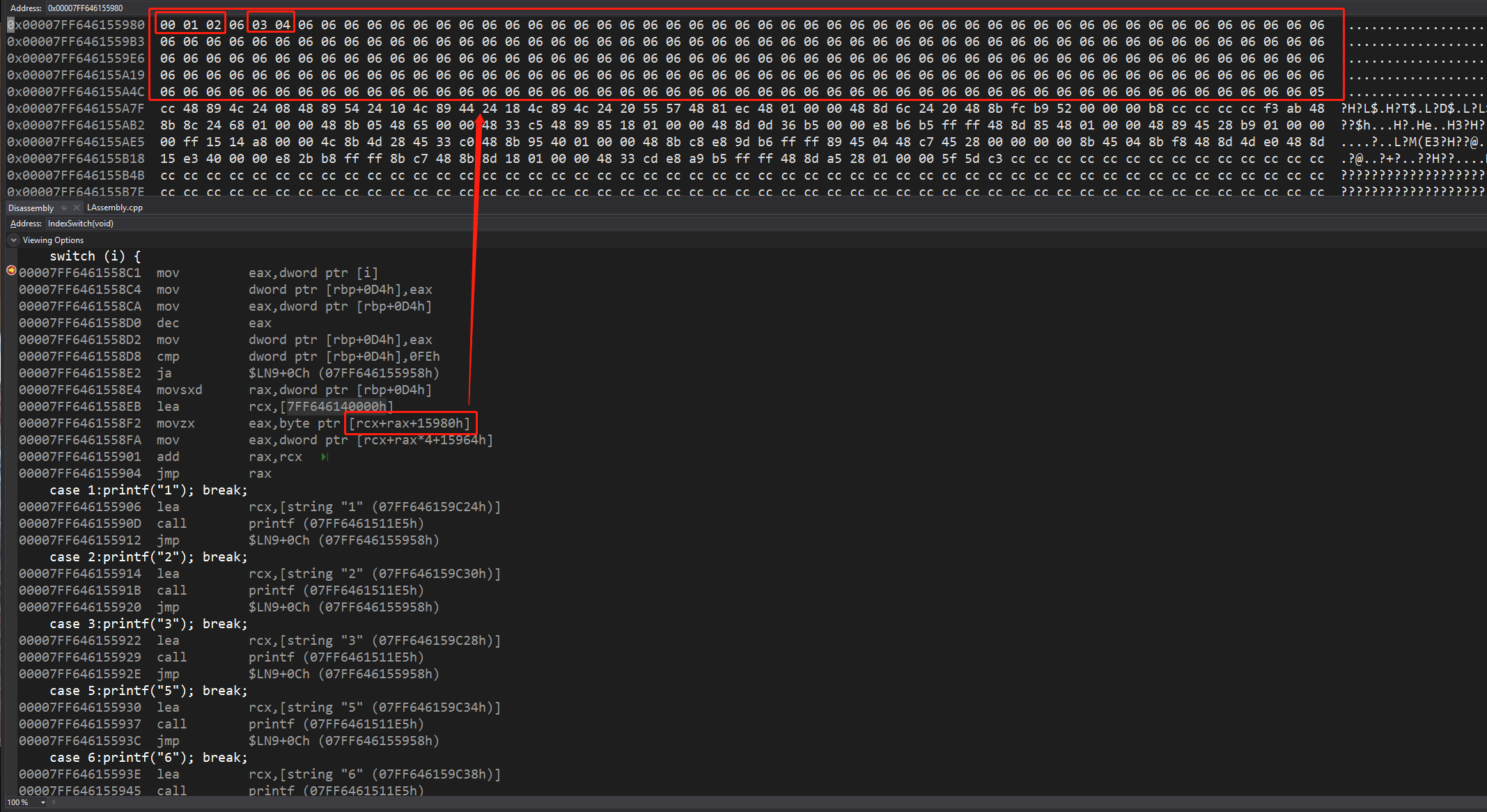
先根据变量查询索引表,索引表最多256位,而且每一项只占用1字节
这里可以看到,中空的4标签与default标签一样,都属于第6项
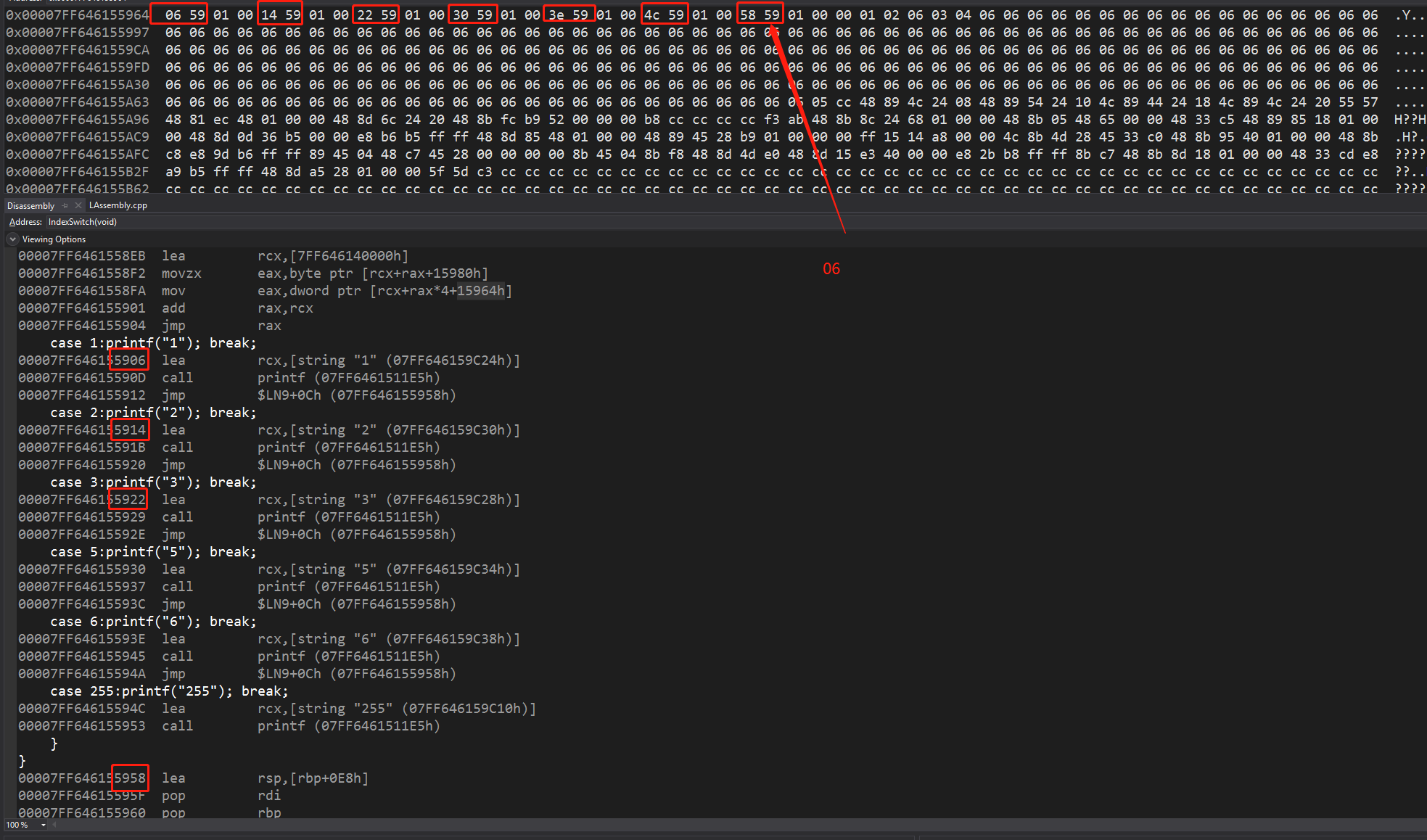
地址表的第6项就是结尾
switch语句的树状优化
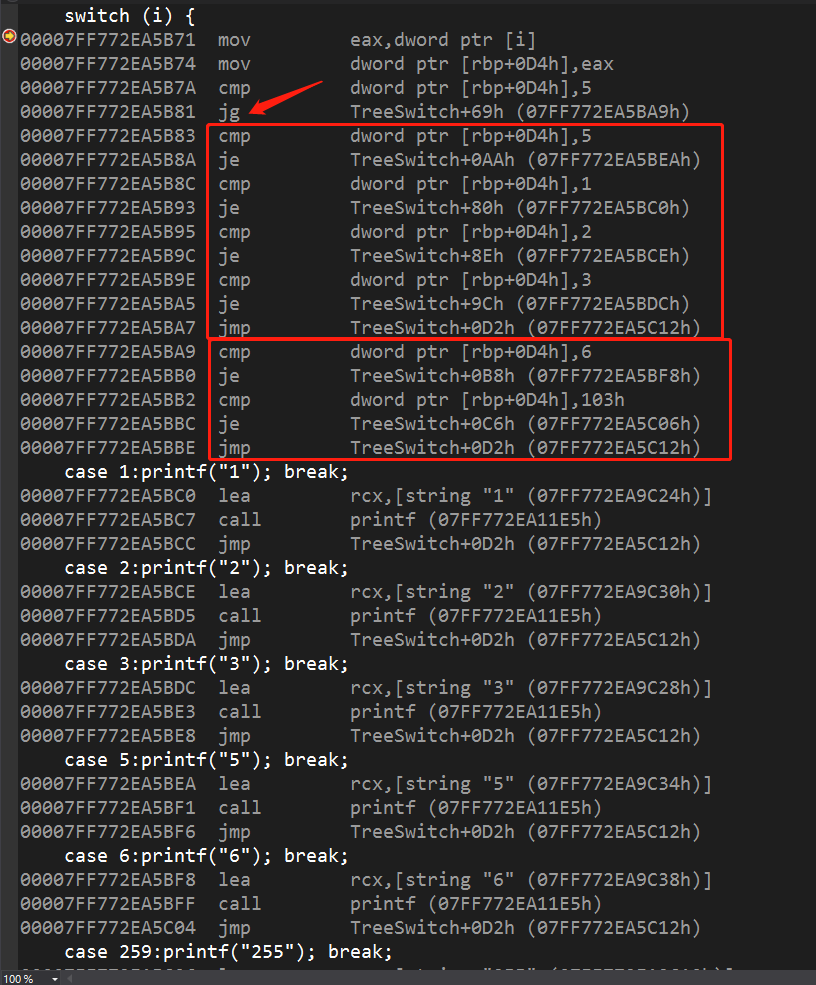
还原出来的树如下
1 | 5 |
降低树的高度
编译器会使用上方的三种方法优化(替换成if语句、线性优化、索引优化)尝试优化左右子树来降低树的高度
循环
Debug版
do循环
1 | DO_BEGIN: |
while循环
1 | WHILE_BEGIN: |
while比do多用了一条跳转指令,因此效率比do低
for循环
1 | mov mem/reg, xxx ; 初值 |
最难读懂
从结构特征可以看出,从效率上来说 do > while > for
Release 优化
while循环
while循环与do循环的区别就在于是否先判断条件,因此while循环等价于
1 | if (XXX){ |
Release版本下,编译器就是这样将while循环结构改成单分支结构加上do循环结构
for循环
for的循环结构与while的循环结构相似,实际上将赋初值外提,对变量的操作放到循环体内,完全完全可以等价于while循环
1 | for (int i = 0; i < 5; i++){ |
既然for循环能转换为while循环,while循环能转换为do循环,因此for循环最后也会转换成do循环。事实上也正是如此,所以在逆向过程中,一般都很难还原成for类型的循环,只能尽量等价
与设备无关的优化方案
中间代码生成阶段优化方案
常量折叠
1 | x = 1 + 2; |
没必要生成加法指令,直接x = 3
常量传播
1 | x = i * 2; |
对xy的比较可以等价于对ij的比较,直接if (i < j)
公共表达式
1 | x = i * 2; |
i * 2是公共表达式,直接y = x
复写传播
1 | x = a; |
没有修改x,直接y = a + c
剪去不可达分支
1 | if (1 > 2){ |
不可达,直接删除if代码块
顺序语句代替分支
例如除法中的条件表达式优化
强度削弱
例如加法或者移位代替乘法,乘法移位代替除法
数学变换
1 | x = a * y + b * y; |
等价于x = (a + b) * y,缩减成1次加法1次乘法
代码外提
1 | while (x < y / 2) { |
不必每次判断都做一次除法,等价于
1 | t = y / 2; |
目标代码生成阶段优化方案
流水线优化
支持流水线的处理器并不会顺序执行指令。在保证计算结果正确的前提下,流水线A在处理第一条指令时,若第二条指令无关,则流水线B会提前处理第二条指令,以提高寄存器的使用率
分支优化规则
引入流水线工作机制后,处理器增加一个分支目标缓冲器。遇到分支结构,利用分支目标缓冲器预测并读取指令目标地址,并进行表格化管理,一次可以记录多个跳转地址。当发生跳转时,查表,找到有则表示并行成功
高速缓存
几层Cache